In this guide, we’ll cover the basics of Stitch billing, how to check and understand your usage, and some tips for keeping your row count low.
In this guide, we’ll cover:
Stitch billing basics
How does Stitch billing work?
Much like the data part of a cell phone plan, each Stitch plan is allotted a certain number of replicated rows per month. For detailed info on pricing and what’s included in each plan, refer to the pricing page on our website.
What's a replicated row?
Stitch counts the following as a ‘replicated row’:
- A new row, or a never-before-replicated row replicated through Stitch,
- An updated row, or an existing row that’s been changed,
- A sub-row created from de-nesting nested data structures, and
- A copy of an existing row. For example: Rows in tables that are replicated fully during each replication job or rows replicated as a result of resetting Replication Keys.
Understand your usage
Source rows ≠ replicated rows
When viewing the number of replicated rows in Stitch, you may be surprised by the totals. You may ask yourself:
“How did Stitch replicate this many rows? There aren’t that many in my source or destination!”
We understand that this can be confusing. Keep in mind that row usage in Stitch is the total number of replicated rows. This means that the number of rows in the source won’t necessarily be equal to your row usage in Stitch.
Because Stitch counts updated rows, copies of existing rows, and rows created from de-nesting towards your total usage, the total of replicated rows and the total number of rows in your data sources or destination may not be equal.
Take the following example. As you can see in the second replication job, the total replicated rows reported by Stitch are cumulative, or the total rows replicated across all replication jobs.
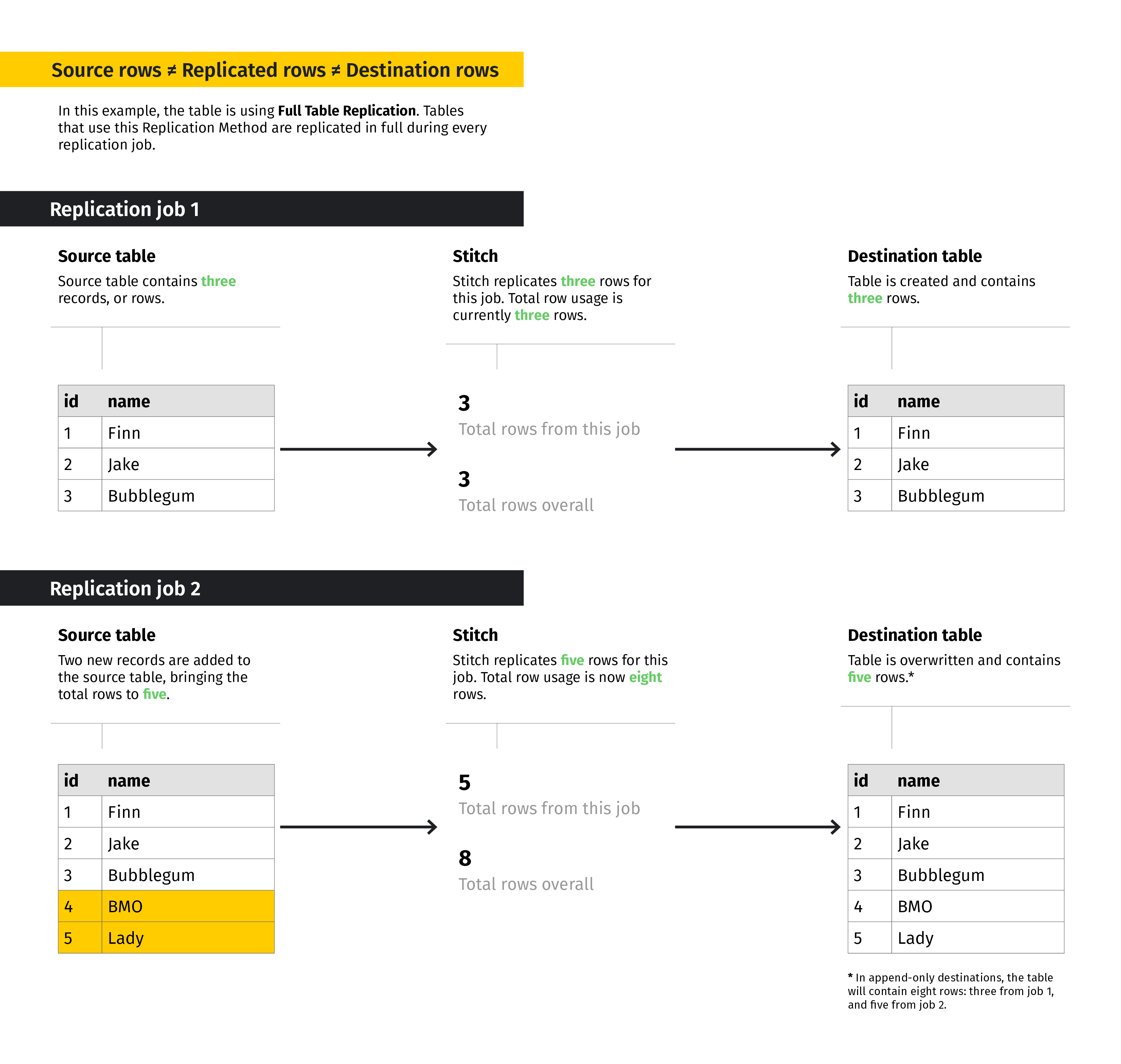
Click to enlarge.
Impacts on usage
The number of rows Stitch replicates is directly impacted by:
-
The number of tables set to replicate. The more tables that you select, the potential higher number of rows.
-
The Replication Methods used by the replicating tables. Tables using Full Table Replication can increase your row usage.
-
Integrations’ replication schedules. Integrations scheduled to replicate on a frequent basis can lead to increased row usage.
-
The volume and structure of the data in the selected tables. Some Stitch destinations - like Redshift and PostgreSQL - will break apart nested records and count each sub-record as a row. Refer to the Nested data structures guide for more info and examples.
Usage examples
Next, we’ll look at some examples of how certain factors can affect row usage in Stitch.
When looking at the examples, note the differences between the source rows and row totals reported in Stitch.
In each tab is an example of how certain factors can affect row usage in Stitch.
For these examples, assume that:
- The tables are using Full Table Replication. This means the table is replicated in full during every replication job.
- That Extraction has completed without issue for every scheduled replication job.
In this example, we’ll look at how different replication frequencies can affect the total number of replicated rows.
Below are the total number of replicated rows for a table with 100 rows using Full Table Replication:
| Replication Frequency | 30 minutes | 1 hour | 6 hours | 12 hours | 24 hours |
| Daily total | 4,800 | 2,400 | 400 | 200 | 100 |
| Billing period total | 144,000 | 72,000 | 12,000 | 6,000 | 3,000 |
As you can see, slightly reducing the Replication Frequency can greatly reduce the number of replicated rows overall.
While this example only demonstrates row usage for a single table, think about how row usage will increase when there are multiple tables like this one set to replicate.
Note: This example is applicable only to destinations that don’t natively support nested data, such as Amazon Redshift or PostgreSQL-based destinations.
In this example, we’ll look at how data structured using JSON arrays can affect the total number of replicated rows.
For destinations that don’t natively support storing nested data, Stitch will “de-nest”, or normalize, complex JSON structures into relations. For JSON arrays, data is unpacked into subtables, where each sub-record is counted as a replicated row.
Source record in JSON format
When Stitch extracts data from a source, it's done by putting the data into JSON format. Below is a sample record from a table named people. Note the best_friends array:
{
"id":1,
"name":"Finn",
"type":"human",
"best_friends":[
{
"id":2,
"name":"Jake",
"type":"dog"
},
{
"id":3,
"name":"Bubblegum",
"type":"princess"
},
{
"id":4,
"name":"BMO",
"type":"robot"
}
]
}
When Stitch loads this record into the destination, two tables will be created: people and people__best_friends. This is due to Stitch unpacking the JSON arrays.
people
The top-level table will contain a single record:
| id | name | type |
| 1 | Finn | human |
people__best_friends
The subtable will contain three records, one for each item in the best_friends array:
| _sdc_source_key_id | _sdc_level_0_id | id | name | type |
| 1 | 0 | 2 | Jake | dog |
| 1 | 1 | 3 | Bubblegum | princess |
| 1 | 2 | 4 | BMO | robot |
This example assumes the table is using Full Table Replication. Below are the total number of replicated rows for the people (one record) and people__best_friends (three records) tables:
| 30 minutes | 1 hour | 6 hours | 12 hours | 24 hours | |
| Daily total | 192 | 96 | 16 | 8 | 4 |
| Billing period total | 5,760 | 2,880 | 480 | 240 | 120 |
This example demonstrates that while there is only one record in the source, the number of rows replicated and loaded through Stitch will be four due to de-nesting.
While the example totals may not appear to be significant, think about this as it might relate to real data. Tables can contain dozens or hundreds of records, which will exponentially increase overall row usage.
Check your row usage
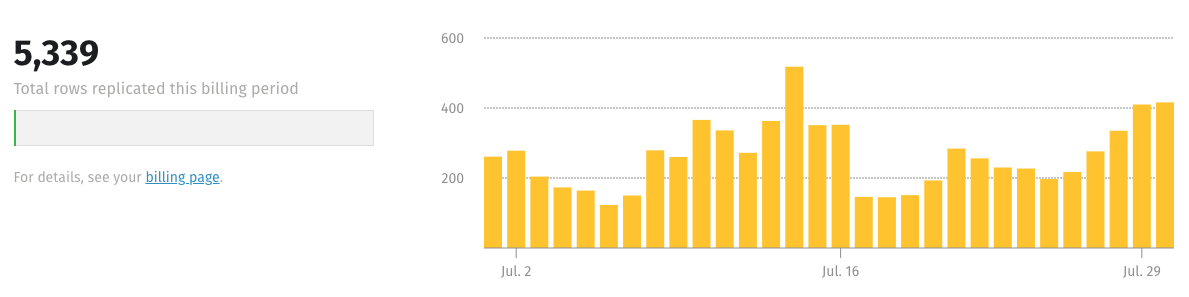
Row usage for all integrations
On the Stitch Dashboard page, you can view the total number of replicated rows for all of your integrations for the current billing period:
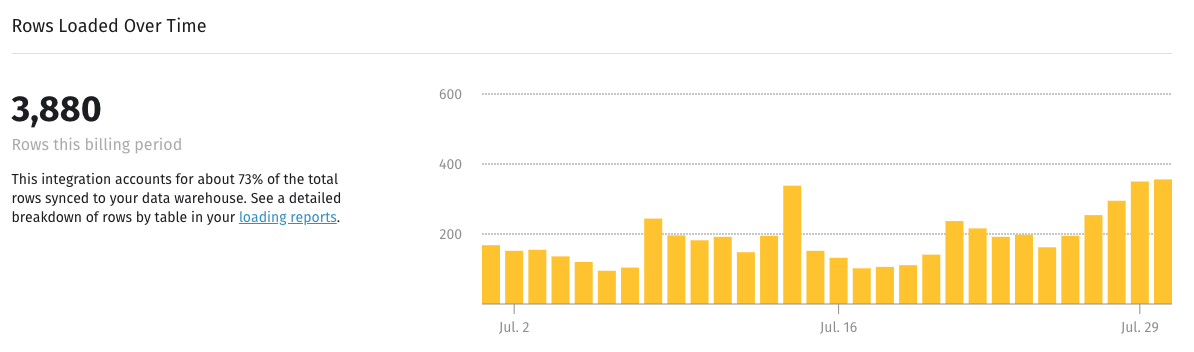
Row usage for an integration
To take a closer look at an individual integration’s usage for the current billing period, click on the integration to open the Integration Details page, and check out the Rows Loaded Over Time section:
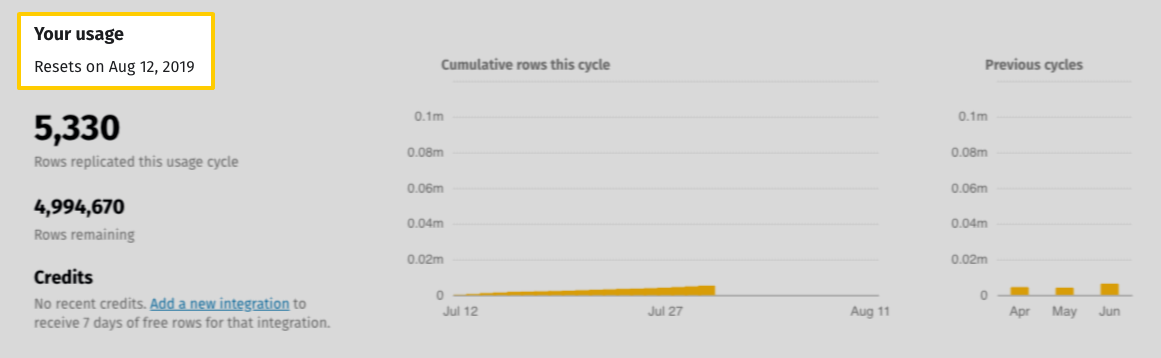
Row usage reset date
The reset date - or the day your row count will reset to zero - can be found in the Your Usage section of your Billing page, accessed by clicking the User menu (your icon) > Billing:
Reduce your usage
While you can change your plan at any time to accommodate your data volume needs, below are some tried-and-true tips for reducing your row usage and staying within your plan’s row allotment:
Identify high usage integrations
For many of Stitch’s integrations, row usage shouldn’t be an issue. We attempt to use Key-based Incremental Replication for SaaS integrations whenever possible.
There are, however, times when high row usage may be unavoidable. For example:
-
Data contains many nested structures. This is applicable to row usage only when a destination doesn’t natively support nested JSON structures.
-
Source generates large amounts of data
-
Integration has a high number of tables using Full Table Replication
-
Integration doesn’t currently support table selection
-
Integration uses an for extraction
Click below to display integrations known to be heavy row users, and the potential reasons for their increased usage. If you’re using any of these integrations, you can use the remaining tips in this section to keep your usage down.
To find out more about your SaaS integrations' data structure and replication methods, we recommend checking out our extensive SaaS integration docs. Every SaaS integration has detailed info about the tables Stitch will replicate and the methods used to do so.
| Integration | Reasons |
| Any database |
|
| Club Speed (v1) |
|
| Codat (v1) |
|
| Desk (v15-10-2015) |
|
| Facebook Ads (v1) |
|
| Google Ads (v1) |
|
| Google Ads (AdWords) (v1) |
|
| Google Analytics (AdWords) (v05-12-2017) |
|
| Google ECommerce (v15-10-2015) |
|
| HubSpot (v2) |
|
| JIRA (v2) |
|
| Listrak (v1) |
|
| LivePerson (v1) |
|
| Microsoft Advertising (v2) |
|
| Mixpanel (v1) |
|
| MongoDB (v2) |
|
| MongoDB (v3) |
|
| MongoDB Atlas (v2) |
|
| MongoDB Atlas (v3) |
|
| NetSuite (v2) |
|
| Pepperjam (v1) |
|
| Shopify (v1) |
|
| Stripe (v3) |
|
| Xero (v1) |
|
| Zendesk Support (v2) |
|
Reduce Replication Frequencies
Generally, the more often an integration is scheduled to replicate, the higher the number of rows Stitch replicates for the inetgration.
If you’re able to get by without the freshest data, consider changing your integrations’ Replication Frequency to something less frequent. For example: Every hour or six hours.
Keep in mind that the Replication Frequency setting applies to the entire integration, not individual tables. This is especially important if there are a lot of tables that use Full Table Replication in the integration.
Use an incremental Replication Method
For integrations that support Replication Method configuration, we recommend using either Key-based or Log-based Incremental Replication whenever possible.
De-select unnecessary data
Note: This is only applicable to the integrations that support table and/or column selection.
To keep your row count down and your destination tidy, you can also de-select any tables or columns you don’t need.
For example: If a column contains nested data, additional sub-rows may be created to accommodate loading the data to certain destination types. This will increase the total row count, as Stitch counts sub-rows towards usage. If this column is no longer needed, you could de-select it and lower your usage.
Pause integrations
If all else fails, you can temporarily pause the integration to keep from going over your row limit.
Note: Pausing an integration will only prevent the extraction of additional records. Loading will continue for records that have been extracted prior to the pause.
For example: If there are records currently in Preparing when an integration is paused, Stitch will continue to load these records, complete the current replication job, and count them towards your usage.
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.