This integration is powered by Singer's JIRA tap and certified by Stitch. Check out and contribute to the repo on GitHub.
For support, contact Stitch support.
JIRA integration summary
Stitch’s JIRA integration replicates data from a JIRA Cloud instance using the JIRA Cloud REST API v2. Refer to the Schema section for a list of objects available for replication.
JIRA feature snapshot
A high-level look at Stitch's JIRA (v1) integration, including release status, useful links, and the features supported in Stitch.
| STITCH | |||
| Release status |
Deprecated on February 28, 2020 |
Supported by | |
| Stitch plan |
Standard |
API availability |
Not available |
| Singer GitHub repository | |||
| REPLICATION SETTINGS | |||
| Anchor Scheduling |
Supported |
Advanced Scheduling |
Supported |
| Table-level reset |
Unsupported |
Configurable Replication Methods |
Unsupported |
| DATA SELECTION | |||
| Table selection |
Supported |
Column selection |
Supported |
| Select all |
Supported |
||
| TRANSPARENCY | |||
| Extraction Logs |
Supported |
Loading Reports |
Supported |
Connecting JIRA
JIRA setup requirements
To set up JIRA in Stitch, you need:
-
Access to the issues, projects, worklogs, etc. that you want to replicate. Stitch is only able to access the same objects that the user authenticating the integration has access to. If this user doesn’t have access to specific datasets or records, Stitch will be unable to replicate them from JIRA. Refer to JIRA’s documentation for more info about permissions in JIRA.
Step 1: Verify self-managed configuration
Step 1.1: Verify your protocol support
To connect to a self-managed JIRA instance, your server must use HTTPs as the protocol. Stitch does not support HTTP for security reasons.
When you complete the JIRA setup in Stitch, you’ll be asked to enter your JIRA base URL. If Stitch determines that the protocol is not HTTPs, connection errors will arise.
Before proceeding, verify that your server uses HTTPs as the protocol.
Step 1.2: Whitelist Stitch's IP addresses
If your self-managed JIRA instance is behind a firewall, you’ll also need to whitelist Stitch’s IP addresses before proceeding. This ensures that Stitch will be allowed to access the instance. If you’re unsure how to do this, contact a member of your technical team for assistance.
The IP addresses you’ll whitelist depend on the Data pipeline region your account is in.
- Sign into your Stitch account, if you haven’t already.
- Click User menu (your icon) > Manage Account Settings and locate the Data pipeline region section to verify your account’s region.
-
Locate the list of IP addresses for your region:
- Whitelist the appropriate IP addresses for your Stitch data pipeline region.
Step 2: Generate a JIRA API token
To authenticate with a cloud-hosted JIRA instance, Stitch requires a JIRA username and an API token. In this step, you’ll generate an API token in JIRA.
- Sign into your JIRA account.
- Click the user menu (your icon) in the bottom left corner of the page.
- Click Profile.
- Click Manage your account.
- Click the Security tab.
- In the API token section, click the Create and manage API tokens link.
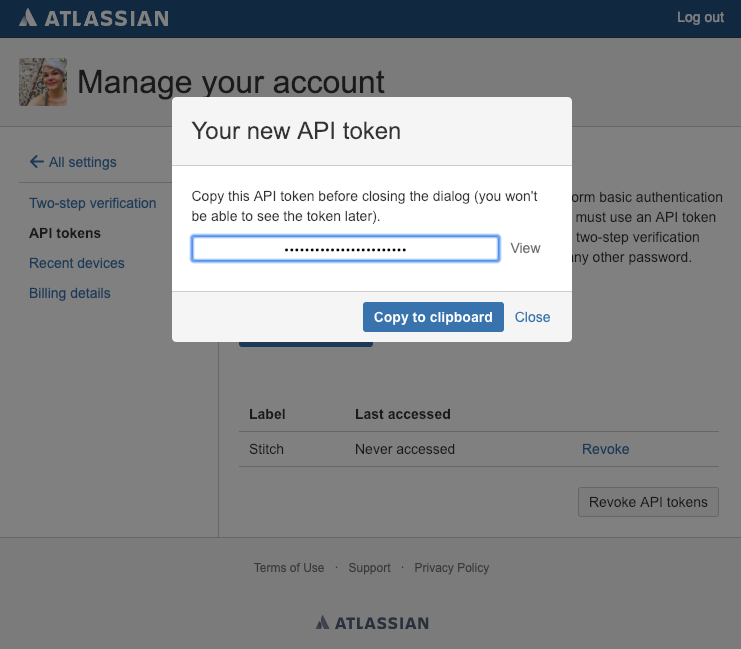
- On the page that displays, click the Create API token button.
- In the window that displays, enter a Label for the API token. For example:
Stitch - Click Create.
- A new window containing the API token will display. Copy the token before closing the window, as JIRA will only display it once.
Step 3: Add JIRA as a Stitch data source
- Sign into your Stitch account.
-
On the Stitch Dashboard page, click the Add Integration button.
-
Click the JIRA icon.
-
Enter a name for the integration. This is the name that will display on the Stitch Dashboard for the integration; it’ll also be used to create the schema in your destination.
For example, the name “Stitch JIRA” would create a schema called
stitch_jirain the destination. Note: Schema names cannot be changed after you save the integration. -
In the Base URL field, enter the base URL for your JIRA site. For example:
stitchdata.atlassian.netorstitchdata.atlassian.comNote: If you’re connecting a self-managed instance, your server must use the
HTTPsprotocol or Stitch will be unable to successfully connect. - In the Username field, enter the email address of the JIRA user you want to use to authenticate the integration. Note: Stitch will replicate only the issues, projects, worklogs, etc. that this user has access to. If this user doesn’t have access to specific datasets or records, Stitch will be unable to replicate them from JIRA.
- In the Password or Token field:
- If connecting a self-managed JIRA instance, enter the password associated with the user in the Username field.
- If connecting a cloud-hosted JIRA instance, paste the API token you generated in Step 2.
Step 4: Define the historical replication start date
The Sync Historical Data setting defines the starting date for your JIRA integration. This means that data equal to or newer than this date will be replicated to your data warehouse.
Change this setting if you want to replicate data beyond JIRA’s default setting of 1 year. For a detailed look at historical replication jobs, check out the Syncing Historical SaaS Data guide.
Step 5: Create a replication schedule
In the Replication Frequency section, you’ll create the integration’s replication schedule. An integration’s replication schedule determines how often Stitch runs a replication job, and the time that job begins.
JIRA integrations support the following replication scheduling methods:
-
Advanced Scheduling using Cron (Advanced or Premium plans only)
To keep your row usage low, consider setting the integration to replicate less frequently. See the Understanding and Reducing Your Row Usage guide for tips on reducing your usage.
Step 6: Set objects to replicate
The last step is to select the tables and columns you want to replicate. Learn about the available tables for this integration.
Note: If a replication job is currently in progress, new selections won’t be used until the next job starts.
For JIRA integrations, you can select:
-
Individual tables and columns
-
All tables and columns
Click the tabs to view instructions for each selection method.
- In the integration’s Tables to Replicate tab, locate a table you want to replicate.
-
To track a table, click the checkbox next to the table’s name. A blue checkmark means the table is set to replicate.
-
To track a column, click the checkbox next to the column’s name. A blue checkmark means the column is set to replicate.
- Repeat this process for all the tables and columns you want to replicate.
- When finished, click the Finalize Your Selections button at the bottom of the screen to save your selections.
- Click into the integration from the Stitch Dashboard page.
-
Click the Tables to Replicate tab.
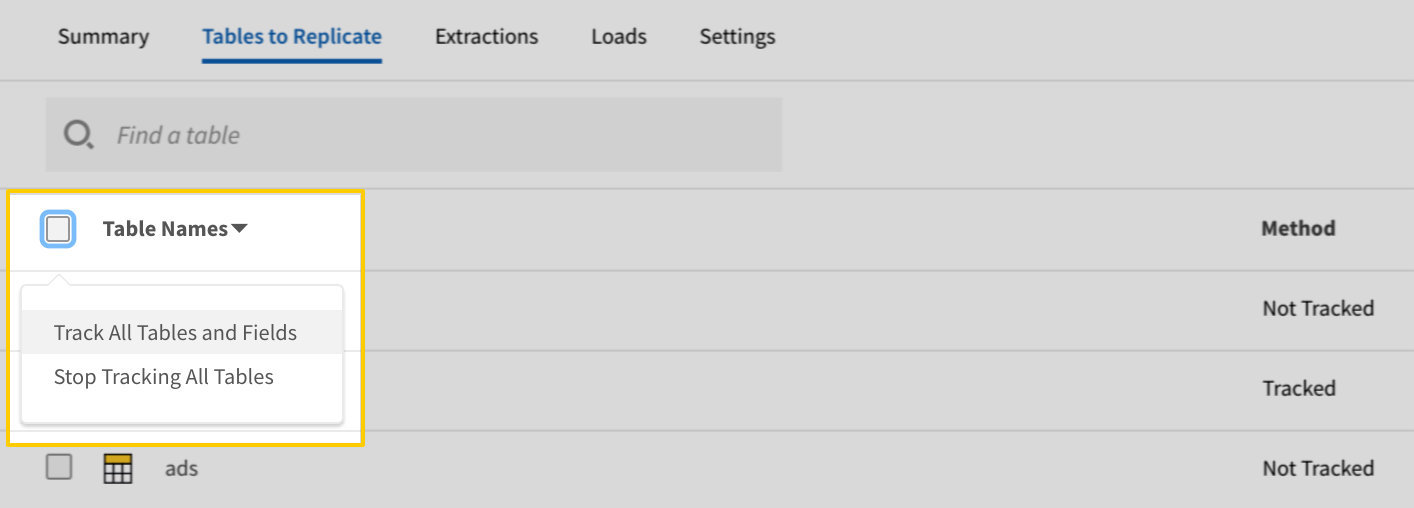
- In the list of tables, click the box next to the Table Names column.
-
In the menu that displays, click Track all Tables and Fields:
- Click the Finalize Your Selections button at the bottom of the page to save your data selections.
Initial and historical replication jobs
After you finish setting up JIRA, its Sync Status may show as Pending on either the Stitch Dashboard or in the Integration Details page.
For a new integration, a Pending status indicates that Stitch is in the process of scheduling the initial replication job for the integration. This may take some time to complete.
Initial replication jobs with Anchor Scheduling
If using Anchor Scheduling, an initial replication job may not kick off immediately. This depends on the selected Replication Frequency and Anchor Time. Refer to the Anchor Scheduling documentation for more information.
Free historical data loads
The first seven days of replication, beginning when data is first replicated, are free. Rows replicated from the new integration during this time won’t count towards your quota. Stitch offers this as a way of testing new integrations, measuring usage, and ensuring historical data volumes don’t quickly consume your quota.
JIRA table reference
Schemas and versioning
Schemas and naming conventions can change from version to version, so we recommend verifying your integration’s version before continuing.
The schema and info displayed below is for version 1 of this integration.
Table and column names in your destination
Depending on your destination, table and column names may not appear as they are outlined below.
For example: Object names are lowercased in Redshift (CusTomERs > customers), while case is maintained in PostgreSQL destinations (CusTomERs > CusTomERs). Refer to the Loading Guide for your destination for more info.
changelogs
The changelogs table contains info about the changelogs associated with an issue.
Replication requirements
To replicate this data:
-
The
issuestable must also be set to replicate. Note: When an issue is updated, all the changelogs for that issue will also be replicated. -
The
Browse Projectsproject JIRA permission is required. Refer to JIRA’s API documentation for more info.
|
Key-based Incremental |
|
|
Primary Key |
id |
| Useful links |
| Join changelogs with | on |
|---|---|
| issue_comments |
changelogs.issueId = issue_comments.issueId changelogs.author.key = issue_comments.author.key changelogs.author.key = issue_comments.updateAuthor.key |
| issue_transitions |
changelogs.issueId = issue_transitions.issueId |
| issues |
changelogs.issueId = issues.id changelogs.author.key = issues.fields.attachment.author.key |
| worklogs |
changelogs.issueId = worklogs.issueId changelogs.author.key = worklogs.author.key changelogs.author.key = worklogs.updateAuthor.key |
| projects |
changelogs.author.key = projects.components.assignee.key changelogs.author.key = projects.components.lead.key changelogs.author.key = projects.components.realAssignee.key changelogs.author.key = projects.lead.key |
| users |
changelogs.author.key = users.key |
|
author OBJECT |
|||||||||||||||||||||||||||||
|
created DATE-TIME |
|||||||||||||||||||||||||||||
|
historyMetadata OBJECT
|
|||||||||||||||||||||||||||||
|
id
STRING |
|||||||||||||||||||||||||||||
|
issueId STRING |
|||||||||||||||||||||||||||||
|
items ARRAY
|
issue_comments
The issue_comments table contains info about comments made on issues.
Replication requirements
To replicate this data:
- The
issuestable must also be set to replicate. Note: When an issue is updated, all the comments for that issue will also be replicated. - The
Browse Projectsproject JIRA permission is required. Refer to JIRA’s API documentation for more info.
|
Key-based Incremental |
|
|
Primary Key |
id |
| Useful links |
| Join issue_comments with | on |
|---|---|
| changelogs |
issue_comments.issueId = changelogs.issueId issue_comments.author.key = changelogs.author.key issue_comments.updateAuthor.key = changelogs.author.key |
| issue_transitions |
issue_comments.issueId = issue_transitions.issueId |
| issues |
issue_comments.issueId = issues.id issue_comments.author.key = issues.fields.attachment.author.key issue_comments.updateAuthor.key = issues.fields.attachment.author.key |
| worklogs |
issue_comments.issueId = worklogs.issueId issue_comments.author.key = worklogs.author.key issue_comments.updateAuthor.key = worklogs.author.key issue_comments.author.key = worklogs.updateAuthor.key issue_comments.updateAuthor.key = worklogs.updateAuthor.key |
| projects |
issue_comments.author.key = projects.components.assignee.key issue_comments.updateAuthor.key = projects.components.assignee.key issue_comments.author.key = projects.components.lead.key issue_comments.updateAuthor.key = projects.components.lead.key issue_comments.author.key = projects.components.realAssignee.key issue_comments.updateAuthor.key = projects.components.realAssignee.key issue_comments.author.key = projects.lead.key issue_comments.updateAuthor.key = projects.lead.key |
| users |
issue_comments.author.key = users.key issue_comments.updateAuthor.key = users.key |
|
author OBJECT |
||
|
body STRING |
||
|
created DATE-TIME |
||
|
id
STRING |
||
|
issueId STRING |
||
|
jsdPublic BOOLEAN |
||
|
properties ARRAY
|
||
|
renderedBody STRING |
||
|
self STRING |
||
|
updateAuthor OBJECT |
||
|
updated DATE-TIME |
||
|
visibility OBJECT
|
issue_transitions
The issue_transitions table contains info about issue transitions.
Replication requirements
To replicate this data:
- The
issuestable must also be set to replicate. Note: When an issue is updated, all the transitions for that issue will also be replicated. - The
Browse Projectsproject JIRA permission is required. Refer to JIRA’s API documentation for more info.
|
Key-based Incremental |
|
|
Primary Key |
id |
| Useful links |
| Join issue_transitions with | on |
|---|---|
| changelogs |
issue_transitions.issueId = changelogs.issueId |
| issue_comments |
issue_transitions.issueId = issue_comments.issueId |
| issues |
issue_transitions.issueId = issues.id |
| worklogs |
issue_transitions.issueId = worklogs.issueId |
|
expand STRING |
||||||||||||
|
fields OBJECT |
||||||||||||
|
hasScreen BOOLEAN |
||||||||||||
|
id
STRING |
||||||||||||
|
isConditional BOOLEAN |
||||||||||||
|
isGlobal BOOLEAN |
||||||||||||
|
isInitial BOOLEAN |
||||||||||||
|
issueId STRING |
||||||||||||
|
name STRING |
||||||||||||
|
to OBJECT
|
issues
The issues table contains info about the issues in your JIRA instance. This table only contains core issue data - some data is located in other tables, such as changelogs, issue_comments, and issue_transitions.
Note: To replicate this data, the Browse projects project JIRA permission for the project that the issue is in is required. Refer to JIRA’s API documentation for more info.
Identifying deleted issues
When an issue is hard-deleted in JIRA, the record for the issue will remain in your destination. This is due to the nature of Stitch Replication Keys and the design of JIRA’s API:
- Replication Keys: This table uses the values in the `` column to identify new and updated data for replication. If a record is hard-deleted, there won’t be a value for Stitch to check and thus no way to identify the change, meaning the record will remain in the destination.
- JIRA’s API: Currently, JIRA’s API doesn’t include a way to identify deleted issues.
To identify deleted issues, Atlassian’s suggested workaround is:
- Create a status in JIRA that will be applied to issues you want to delete.
- Before deleting the issue, apply the status.
- Allow Stitch to extract and load the updated data into your destination.
- Delete the issue.
-
After Stitch finishes loading the data, use the
fields__status__namefield in your queries to filter issues with the deleted status you applied in step 2. For example, the following query would return any issues that had been marked with a the deleted status:SELECT * FROM stitch_jira.issues WHERE fields__status__name = 'Deleted'
|
Key-based Incremental |
|
|
Primary Key |
id |
| Useful links |
| Join issues with | on |
|---|---|
| changelogs |
issues.id = changelogs.issueId issues.fields.attachment.author.key = changelogs.author.key |
| issue_comments |
issues.id = issue_comments.issueId issues.fields.attachment.author.key = issue_comments.author.key issues.fields.attachment.author.key = issue_comments.updateAuthor.key |
| issue_transitions |
issues.id = issue_transitions.issueId |
| worklogs |
issues.id = worklogs.issueId issues.fields.attachment.author.key = worklogs.author.key issues.fields.attachment.author.key = worklogs.updateAuthor.key |
| projects |
issues.fields.attachment.author.key = projects.components.assignee.key issues.fields.attachment.author.key = projects.components.lead.key issues.fields.attachment.author.key = projects.components.realAssignee.key issues.fields.attachment.author.key = projects.lead.key |
| users |
issues.fields.attachment.author.key = users.key |
|
editmeta OBJECT
|
||||
|
expand STRING |
||||
|
fields OBJECT
|
||||
|
fieldsToInclude OBJECT |
||||
|
id
STRING |
||||
|
key STRING |
||||
|
names OBJECT |
||||
|
properties OBJECT
|
||||
|
renderedFields OBJECT |
||||
|
schema OBJECT |
||||
|
self STRING |
||||
|
versionedRepresentations OBJECT |
project_categories
The project_categories table contains info about project categories.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join project_categories with | on |
|---|---|
| projects |
project_categories.id = projects.projectCategory.id |
|
description STRING |
|
id
STRING |
|
name STRING |
|
self STRING |
project_types
The project_types table contains info about project types.
|
Full Table |
|
|
Primary Key |
key |
| Useful links |
|
color STRING |
|
descriptionI18nKey STRING |
|
formattedKey STRING |
|
icon STRING |
|
key
STRING |
projects
The projects table contains info about projects in your JIRA account.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join projects with | on |
|---|---|
| project_categories |
projects.projectCategory.id = project_categories.id |
| versions |
projects.id = versions.projectId |
| changelogs |
projects.components.assignee.key = changelogs.author.key projects.components.lead.key = changelogs.author.key projects.components.realAssignee.key = changelogs.author.key projects.lead.key = changelogs.author.key |
| issue_comments |
projects.components.assignee.key = issue_comments.author.key projects.components.lead.key = issue_comments.author.key projects.components.realAssignee.key = issue_comments.author.key projects.lead.key = issue_comments.author.key projects.components.assignee.key = issue_comments.updateAuthor.key projects.components.lead.key = issue_comments.updateAuthor.key projects.components.realAssignee.key = issue_comments.updateAuthor.key projects.lead.key = issue_comments.updateAuthor.key |
| issues |
projects.components.assignee.key = issues.fields.attachment.author.key projects.components.lead.key = issues.fields.attachment.author.key projects.components.realAssignee.key = issues.fields.attachment.author.key projects.lead.key = issues.fields.attachment.author.key |
| users |
projects.components.assignee.key = users.key projects.components.lead.key = users.key projects.components.realAssignee.key = users.key projects.lead.key = users.key |
| worklogs |
projects.components.assignee.key = worklogs.author.key projects.components.lead.key = worklogs.author.key projects.components.realAssignee.key = worklogs.author.key projects.lead.key = worklogs.author.key projects.components.assignee.key = worklogs.updateAuthor.key projects.components.lead.key = worklogs.updateAuthor.key projects.components.realAssignee.key = worklogs.updateAuthor.key projects.lead.key = worklogs.updateAuthor.key |
|
assigneeType STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
avatarUrls OBJECT |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
components ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
description STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
expand STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
id
STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
issueTypes ARRAY
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
key STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
lead OBJECT
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
name STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
projectCategory OBJECT
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
projectKeys ARRAY |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
projectTypeKey STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
roles OBJECT |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
self STRING |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
simplified BOOLEAN |
||||||||||||||||||||||||||||||||||||||||||||||||||||
|
url STRING |
resolutions
The resolutions table contains info about issue resolutions.
Note: To replicate this data, the Administer JIRA global JIRA permission is required. Refer to JIRA’s API documentation for more info.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
|
description STRING |
|
iconUrl STRING |
|
id
STRING |
|
name STRING |
|
self STRING |
roles
The roles table contains info about the project roles in your JIRA account.
Note: To replicate this data, the Administer JIRA global JIRA permission is required. Refer to JIRA’s API documentation for more info.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
|
actors ARRAY
|
|||||
|
description STRING |
|||||
|
id
INTEGER |
|||||
|
name STRING |
|||||
|
self STRING |
users
The users table contains info about the users in your JIRA account.
Note: To replicate this data, the Administer JIRA global JIRA permission is required. Refer to JIRA’s API documentation for more info.
|
Full Table |
|
|
Primary Key |
key |
| Useful links |
| Join users with | on |
|---|---|
| changelogs |
users.key = changelogs.author.key |
| issue_comments |
users.key = issue_comments.author.key users.key = issue_comments.updateAuthor.key |
| issues |
users.key = issues.fields.attachment.author.key |
| projects |
users.key = projects.components.assignee.key users.key = projects.components.lead.key users.key = projects.components.realAssignee.key users.key = projects.lead.key |
| worklogs |
users.key = worklogs.author.key users.key = worklogs.updateAuthor.key |
|
accountId STRING |
|
accountType STRING |
|
active BOOLEAN |
|
avatarUrls OBJECT |
|
displayName STRING |
|
emailAddress STRING |
|
expand STRING |
|
key
STRING |
|
name STRING |
|
self STRING |
|
timeZone STRING |
versions
The versions table contains info about versions in your JIRA account.
Replication requirements
Note: To replicate this data:
- The
projectstable must also be set to replicate, and - The
Browse Projectsproject JIRA permission is required. Refer to JIRA’s API documentation for more info.
|
Full Table |
|
|
Primary Key |
id |
| Useful links |
| Join versions with | on |
|---|---|
| projects |
versions.projectId = projects.id |
|
archived BOOLEAN |
|||||||
|
description STRING |
|||||||
|
expand STRING |
|||||||
|
id
STRING |
|||||||
|
moveUnfixedIssuesTo STRING |
|||||||
|
name STRING |
|||||||
|
operations ARRAY
|
|||||||
|
overdue BOOLEAN |
|||||||
|
project STRING |
|||||||
|
projectId INTEGER |
|||||||
|
releaseDate DATE-TIME |
|||||||
|
released BOOLEAN |
|||||||
|
remotelinks ARRAY
|
|||||||
|
self STRING |
|||||||
|
startDate DATE-TIME |
|||||||
|
userReleaseDate DATE-TIME |
|||||||
|
userStartDate DATE-TIME |
worklogs
The worklogs table contains info about the worklogs in your JIRA account.
Note: For a worklog to be replicated, it must be set as Viewable by All Users, or the integration authenticating user (visible in the integration’s Integration Settings page), must be a member of the project role/group with permission to view the worklog.
If you’re missing worklogs, verify that you have the required permissions to access the worklog.
|
Key-based Incremental |
|
|
Primary Key |
id |
|
Replication Key |
updated |
| Useful links |
| Join worklogs with | on |
|---|---|
| changelogs |
worklogs.issueId = changelogs.issueId worklogs.author.key = changelogs.author.key worklogs.updateAuthor.key = changelogs.author.key |
| issue_comments |
worklogs.issueId = issue_comments.issueId worklogs.author.key = issue_comments.author.key worklogs.updateAuthor.key = issue_comments.author.key worklogs.author.key = issue_comments.updateAuthor.key worklogs.updateAuthor.key = issue_comments.updateAuthor.key |
| issue_transitions |
worklogs.issueId = issue_transitions.issueId |
| issues |
worklogs.issueId = issues.id worklogs.author.key = issues.fields.attachment.author.key worklogs.updateAuthor.key = issues.fields.attachment.author.key |
| projects |
worklogs.author.key = projects.components.assignee.key worklogs.updateAuthor.key = projects.components.assignee.key worklogs.author.key = projects.components.lead.key worklogs.updateAuthor.key = projects.components.lead.key worklogs.author.key = projects.components.realAssignee.key worklogs.updateAuthor.key = projects.components.realAssignee.key worklogs.author.key = projects.lead.key worklogs.updateAuthor.key = projects.lead.key |
| users |
worklogs.author.key = users.key worklogs.updateAuthor.key = users.key |
|
author OBJECT |
||
|
comment STRING |
||
|
created DATE-TIME |
||
|
id
STRING |
||
|
issueId STRING |
||
|
properties ARRAY
|
||
|
self STRING |
||
|
started DATE-TIME |
||
|
timeSpent STRING |
||
|
timeSpentSeconds INTEGER |
||
|
updateAuthor OBJECT |
||
|
updated
DATE-TIME |
||
|
visibility OBJECT
|
| Related | Troubleshooting |
Questions? Feedback?
Did this article help? If you have questions or feedback, feel free to submit a pull request with your suggestions, open an issue on GitHub, or reach out to us.